
It has been a number of months since Ali reported our progress on the engine refactoring project and the integration of Unicode into LiveCode (Slaying the Unicode Monster) and in that time, much has changed. The project is nearly complete and, as Kevin said yesterday, we are approaching a DP release.
Supporting Unicode and international text has required extensive changes throughout the engine – too extensive to cover in a single blog entry – so today I’ll explain the changes to one of the most visible parts of LiveCode: fields.
In the current releases of LiveCode, it is possible to use Unicode text in fields. Unfortunately, it requires special syntax and can be a bit cumbersome to manipulate properly. In addition, the support is fairly rudimentary and doesn’t work properly for languages requiring complex text layout (for example, Arabic).
7.0 will change all that – Unicode text in fields (and throughout the engine) is manipulated the same way as any other text. In fact, the engine doesn’t distinguish between Unicode text and “plain” text anymore – they are both just text. But that’s a story for another time.
 Most of the changes in the field to support Unicode are “below-the-hood” and won’t be immediately apparent. They have, however, allowed for a much greater deal of flexibility in how text in fields is processed and I’ll summarise what this has allowed us to do:
Most of the changes in the field to support Unicode are “below-the-hood” and won’t be immediately apparent. They have, however, allowed for a much greater deal of flexibility in how text in fields is processed and I’ll summarise what this has allowed us to do:
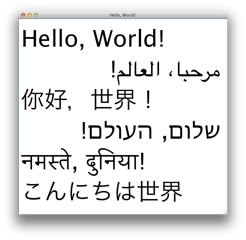
East Asian languages such as Chinese and Japanese. Previously, these could be entered but the field had difficulty with certain characters that required a certain type of Unicode encoding called “surrogate pairs” – the components of these pairs were treated as separate characters, causing problems when one of them was deleted or had its style changed.
Complex scripts where multiple character fragments combine to form one graphical character (called a “grapheme”). For text manipulation, these are now treated as single characters (and new chunk types “codepoint” and “codeunit” have been added for those who need to access the individual components).
Cursor navigation working appropriately for non-English text. Navigating left and right through a field happens on grapheme boundaries, ensuring that the cursor never ends up between a character and its accent. The keyboard commands for moving forwards and backwards by whole words also works for text that doesn’t use spaces as word separators (e.g. Chinese).
Right-to-left and bidirectional text. Mixing left-to-right and right-to-left languages (e.g. Hebrew and Arabic) text in a field now lays text out in the correct order, including the situation when LTR is embedded within RTL or vice-versa.
All of this is available without any extra work on the part of a developer creating a LiveCode app – our goal with our Unicode support is to make it just as easy to create an app with Unicode support as without. We hope you’ll be pleased with the result!
read more
Recent Comments