
It has been a number of months since Ali reported our progress on the engine refactoring project and the integration of Unicode into LiveCode (Slaying the Unicode Monster) and in that time, much has changed. The project is nearly complete and, as Kevin said yesterday, we are approaching a DP release.
Supporting Unicode and international text has required extensive changes throughout the engine – too extensive to cover in a single blog entry – so today I’ll explain the changes to one of the most visible parts of LiveCode: fields.
In the current releases of LiveCode, it is possible to use Unicode text in fields. Unfortunately, it requires special syntax and can be a bit cumbersome to manipulate properly. In addition, the support is fairly rudimentary and doesn’t work properly for languages requiring complex text layout (for example, Arabic).
7.0 will change all that – Unicode text in fields (and throughout the engine) is manipulated the same way as any other text. In fact, the engine doesn’t distinguish between Unicode text and “plain” text anymore – they are both just text. But that’s a story for another time.
 Most of the changes in the field to support Unicode are “below-the-hood” and won’t be immediately apparent. They have, however, allowed for a much greater deal of flexibility in how text in fields is processed and I’ll summarise what this has allowed us to do:
Most of the changes in the field to support Unicode are “below-the-hood” and won’t be immediately apparent. They have, however, allowed for a much greater deal of flexibility in how text in fields is processed and I’ll summarise what this has allowed us to do:
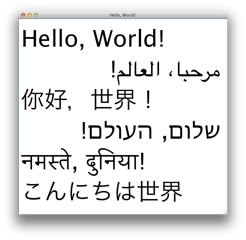
East Asian languages such as Chinese and Japanese. Previously, these could be entered but the field had difficulty with certain characters that required a certain type of Unicode encoding called “surrogate pairs” – the components of these pairs were treated as separate characters, causing problems when one of them was deleted or had its style changed.
Complex scripts where multiple character fragments combine to form one graphical character (called a “grapheme”). For text manipulation, these are now treated as single characters (and new chunk types “codepoint” and “codeunit” have been added for those who need to access the individual components).
Cursor navigation working appropriately for non-English text. Navigating left and right through a field happens on grapheme boundaries, ensuring that the cursor never ends up between a character and its accent. The keyboard commands for moving forwards and backwards by whole words also works for text that doesn’t use spaces as word separators (e.g. Chinese).
Right-to-left and bidirectional text. Mixing left-to-right and right-to-left languages (e.g. Hebrew and Arabic) text in a field now lays text out in the correct order, including the situation when LTR is embedded within RTL or vice-versa.
All of this is available without any extra work on the part of a developer creating a LiveCode app – our goal with our Unicode support is to make it just as easy to create an app with Unicode support as without. We hope you’ll be pleased with the result!
14 comments
Join the conversationPaul Dupuis - February 27, 2014
The text, chunk, and field processing capabilities of LiveCode are essential to our business. We are very much looking forward to these enhancements in 7.0!
Jacque - February 27, 2014
Wow. Just…wow. This is truly exciting. I know how much work it must have been, and I’m sure the entire community is very grateful for your efforts. Thank you.
Alan - February 27, 2014
Fantastic!! Can’t wait! Great work! 😀
Andrew Meit - February 27, 2014
Wow, finally my long, long wait is nearly over. Thank you. Btw, there are some key typography applications that unicode support, will these be there..ie context positions. I am really hoping soon support for kerning/leading will be there. more later… keep it up!!
Fraser Gordon - February 28, 2014
Andrew – I’m not entirely sure what you mean by “context positions” – could you give me an example? (Do you mean things like Zero Width Non-Joiner and Zero Width Joiner or is it something else?)
Manual adjustment of kerning and leading is not something we currently provide but we are intending to improve the typesetting abilities of the engine so it may happen in future.
Mohamed - February 28, 2014
WOW WOW WOW, Thanks a million . this is the time i am waiting for.Right-to-left and bidirectional text , so i can use arabic and extend my license.
Great work
Curt - February 28, 2014
For several years I’ve had three projects in mind that I’ll now be able to dive into when 7.0 with Unicode comes out. Can’t wait! Thanks!!
Igor - March 4, 2014
This is, indeed, wonderful news. It will make Livecode usable in a larger number of projects, and markets. Can’t wait to try it out!
Doron - March 5, 2014
I can’t wait to test these features. Will there still be any points where unicode will not be supported? e.g. content, datagrids, properties etc.?
Fraser Gordon - March 6, 2014
As far as the LiveCode engine is concerned, there are no differences between Unicode text and “normal” text – all text is now Unicode. The intention is that you can use Unicode anywhere you’d expect to be able to enter text.
There may be one or two locations lurking that don’t accept Unicode text; if you find any when 7.0 comes out, please let us know as they were almost certainly unintentional!
Christoph Wollek - March 6, 2014
I am very glad, to hear it: LiveCode will be able, to work with unicode hebrew texts!
In the past I did some tricky work with hebrew texts (font: Shalom Old Style) and I want now to release them in unicode. Will there be any help in transforming these texts?
Best regards,
Christoph.
Fraser Gordon - March 7, 2014
Christoph –
The font you mention works by drawing MacRoman characters as Hebrew characters instead of Latin. Unfortunately, LiveCode has no way of knowing that such a thing is happening as it thinks the characters are in MacRoman and doesn’t know that the font displays them differently.
I’ve had a quick look and it appears that the mapping from MacRoman -> Hebrew done by the font is specific to that font so it is unlikely any tools exist to do the mapping for you. However, it shouldn’t be to difficult to do the conversion yourself in LiveCode:
function convertShalomOldStyleToUnicode pOld
local tUnicode
repeat for each character tToMap in pOld
switch tToMap
case "a" -- Drawn as aleph
put "א" after tUnicode
break
...
end switch
end repeat
return tUnicode
end convertShalomOldStyleToUnicode
Thom Thibeault - March 7, 2014
I’ve been waiting for the LTR capability for years and am VERY excited about this!
haha - April 18, 2014
i hope the documents and the coures are chinese too.
i like livecode very much.
hoho….