
Since we’ve finished the refactoring of the engine, with every functionality working as it should, a performance issue was raised by several community members, on different parts of the new engine. I have been working closely with Ali on this aspect, and here is my take on it, with fewer eggs but a nice musical clef.
We were of course aware of this slowdown, which was mainly caused by the fact the engine was working in a uniform way, regardless of the kind of characters in the strings in use. This consideration of the strings was the first part of the global refactoring plan, to allow us to bring modifications impacting the whole engine instead of micro-changes targeting one area, as had been done on the former versions; the pitfalls behind a single modification were obviously numerous.
Chiefly, the main slowdown comes with the handling of Unicode: there is much, much work to be done any time a string operation is executed. As Fraser explained it in his blog post, Unicode is not simply the ability to use characters out of the ISO-8859-1 encoding. It also comes with all the subtlety of introducing characters longer than one character, be it:
– combining chars, to add as many accents as needed on the same letter (this type of character OS X gives you easily, since it uses the NFD form).
![]() surrogate pairs – who uses music? The treble clef, pictured left, is one of these characters stored as a surrogate pair.
surrogate pairs – who uses music? The treble clef, pictured left, is one of these characters stored as a surrogate pair.
As one may guess, it becomes slightly more difficult to compare two strings when they can be the same, even having a different number of characters – even worse, finding a substring within a string is an operation starting from the beginning, since no character indexing is valid when combining chars or surrogate pairs are present. And since LiveCode users love to use ‘items’, ‘word’, ‘line’ or any of the new chunks introduced in 7.0, it would be best to bring the script executions back to their pre-Unicode timing, when possible.
The main goal has been to avoid as much as possible using the CPU-costly Unicode functions, which boils down to storing more states for a string – is it native, combined, does it include surrogate pairs? This is makes the string operations work differently according to their content, and discards any slowdown which could be caused by Unicode’s intricate rules. In the end, some operations even became faster than they were before – ‘before’ shows it for instance.
In the same way, the engine is now clever enough to keep in mind when a string has been converted to a number. Since a LiveCode variable only stores strings, that is something which comes quite handy when used in a loop, and probably could be tagged as speedup!
Following on the examples coming as bug reports against the slowdown, here is a comparison between 6.6.1 and (future) DP-3:
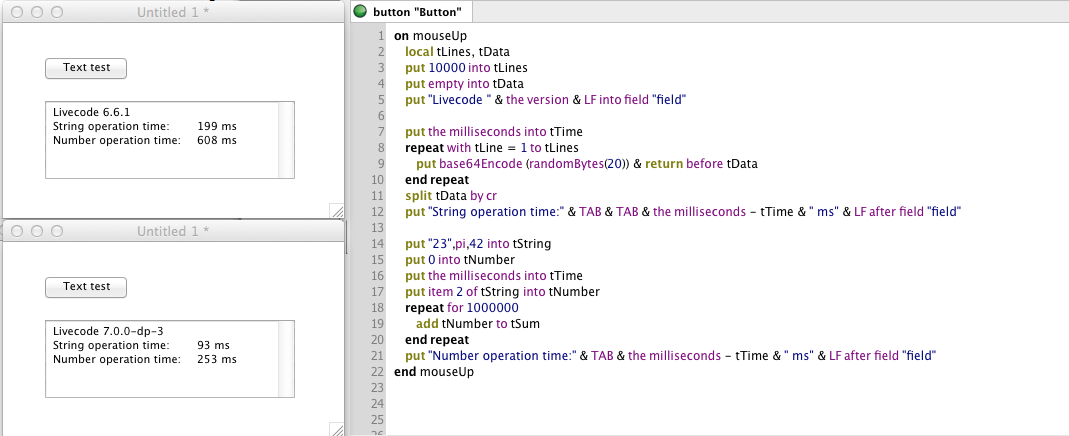
That should have you enjoying the DP-3!
9 comments
Join the conversationJuan José Relaño Laura - April 30, 2014
Juan José Relaño Laura liked this on Facebook.
Toby Justus - April 30, 2014
Toby Justus liked this on Facebook.
Alan Stenhouse - April 30, 2014
Alan Stenhouse liked this on Facebook.
Simon Smith - April 30, 2014
Simon Smith liked this on Facebook.
Pablo Rubio Román - April 30, 2014
Pablo Rubio Román liked this on Facebook.
Mavex Millenium - April 30, 2014
Mavex Millenium liked this on Facebook.
Sulaiman Badmus - April 30, 2014
Sulaiman Badmus liked this on Facebook.
Dar - May 1, 2014
I like the feature of the number value of a string being remembered. That removes the goofy ‘add 0 to sum’ before a loop. Which I never remember. This is also a small mitigation of the parallel loop problem where one is ‘for each’ and the other uses indexes.
Hovhannes Kizoghian - May 13, 2014
Hovhannes Kizoghian liked this on Facebook.