
Reprinted from revUp, read the rest of our twice monthly newsletter here.
When I work in other languages I’ve come to depend on version control to help me keep track of everything. I would like to see the same productivity increases and extra documentation trail that version control provides in my LiveCode projects. Unfortunately LiveCode files are a binary format which is great if you want to pack a lot of data into a small space but not so great if you want to have a version control system work out the difference between two versions of a file. Most version control systems will just decide if a file is text or binary and if it’s binary just treat any difference as a merge conflict.
It is possible to install additional drivers for these systems to deal with binary files or structured data like xml in a better way than line by line processing. Unfortunately hosted repository sites like GitHub and BitBucket would still see the files as binary so we wouldn’t gain benefits like being able to comment on specific changed lines in a script. Apps like SourceTree (Atlassian’s Git/Mercurial client) also wouldn’t be able to show us the differences. So we need a text based file format.
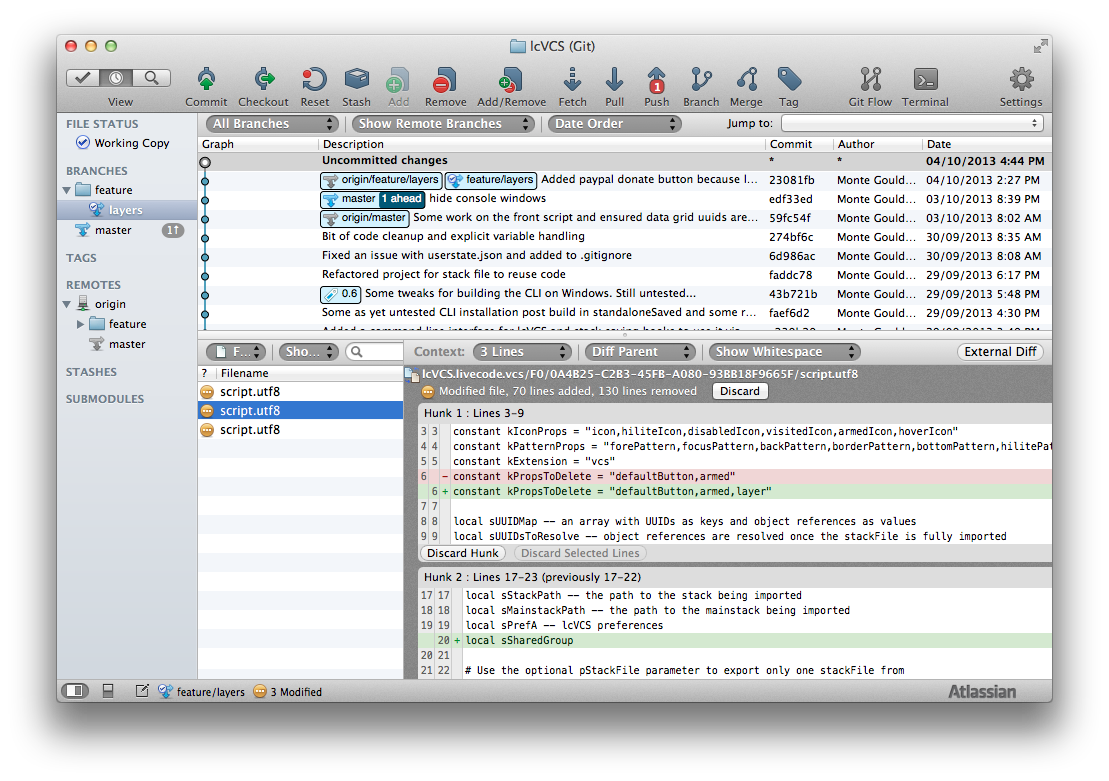
The lcVCS repository in SourceTree (click to zoom)
Towards the end of last year (I’ve been working on this for a while) I decided I would try and crack this nut. Along the way the project (lcVCS) has been a driver for me to do some work on the LiveCode engine including `_internal resolve image`, `the childControlIDs of group|card`, `the cardIDs of group`, `the properties of object` and `is an ascii string`. Additionally I’ve filed half a dozen bug reports on obscure issues that may not otherwise have been identified such as the minuscule rounding error on gradient ramps I found recently. As a result it requires version 6.1.1 of LiveCode.
At first I took a look at what had been done before. Mark Wieder has done a considerable amount of work on this issue with exported stackFiles saved as XML with a directory structure mirroring the stackFile hierarchy. I made contact and told him I was looking at the problem and he has offered a wealth of advice and been my goto guy on this ever since.
I was inspired by Vincent Driessen’s article ‘A successful Git branching model’ so my focus since the beginning has been to ensure we can have multiple development branches of a LiveCode project open at the same time. That means we need to be able to merge these branches so that changes on both are kept. Mark’s work had proved you could reliably export and import a stackFile. When I came to look at the merge issue, however, I hit some rather large roadblocks.
The first and arguably the easiest to overcome is the fact that stackFiles save everything including things that will almost certainly cause merge conflicts like the rects of resizable stacks, text in fields from your last test etc. So if you have two branches of a project and in both you have resized a resizable stack you would have a merge conflict on that… heaven forbid you have a resizeStack handler! My solution was to dispatch a message to each object just before it is exported so it can reset itself to default settings. In practice I usually handle the message in the card script. Anything that is pure session data should be cleared or reset to its default state. Messages are unlocked while the handler is run so your resizeStack handlers or anything else can execute.
The second major issue is one I’m still struggling with. LiveCode objects each have an ID. The stack ID is actually a place holder for the next object ID to be used on a stack. So IDs in stacks are akin to an auto-incrementing primary key in a database. The problems arise when we have multiple branches of the project all creating objects. In each branch the stack is assigning the next available ID. ID’s are a very common way to refer to objects, for example, an image ID is used as the icon reference in a button. So when merging branches of a project we need to ensure that the merge is robust to ID conflicts.
In lcVCS I’ve handled this by assigning every object a UUID (Universally Unique ID) which is basically a random number so large you would need to generate a billion UUIDs a second for 36 years to have a 10% chance of a conflict. Object references are translated into UUIDs to export the stack and when imported they are translated back. This process allows lcVCS to gracefully handle different objects on different branches having the same ID by allowing a new one to be assigned to one of the objects and updating any references to the object.
Unfortunately this isn’t a simple problem. Not only are IDs used as icons, patterns and behaviors they are also often stored in custom properties. For example, the DataGrid stores it’s row template as an ID. To work around this issue I implemented a plugin scheme so that anyone that has a control or library that stores IDs could add support for their custom property set in lcVCS. One day I hope there will be an engine level solution to this problem but I doubt we will see that for a while.
A related issue is when you have a project with multiple stackFiles you need to ensure that they are imported and exported in the correct order so that everything is found. To deal with this I’ve implemented a project file that maintains an ordered list of the stackFiles in your project.
Lately I’ve been working with Trevor DeVore on Clarify 2. Trevor has been very supportive of lcVCS and Clarify 2 is pioneering the use of it on a more complex project than lcVCS itself (lcVCS exports and imports itself which is fun). One of the things I found is that deeply nested groups can create very long paths in a directory structure that mirrors the stackFile hierarchy. On Unix based systems this is fine but Windows can’t handle paths longer than 260 characters so I had to redesign the directory structure to be much shallower. My hope is that the change was the last major re-design lcVCS will need (it’s had many!).
It’s interesting that when you decide to solve one problem you often end up solving others too. Both lcVCS and the mApp framework are LiveCode plugins. I needed to both use the plugins and work on them and the idea of moving the stackFiles from the plugins folder into their Git repositories every time I wanted to export and commit didn’t appeal so I looked for another solution. When I implemented the project file system I found a solution there by allowing the build path to be outside the repository. lcVCS can now import projects directly into the plugins directory or any other directory for that matter. It then dawned on me that if I provided an easy way for users to search for lcVCS projects, install them locally and to switch between branches or tags in the repository that I would have a great way to deliver open source plugins and libraries. A bit of Googling and I found GitHub has a search API, I could search for the lcVCSProject.json file and it would return all the public lcVCS based projects on GitHub. A few shell calls to Git and I had a list of tags (often version numbers) and branches to put in a switch to button.
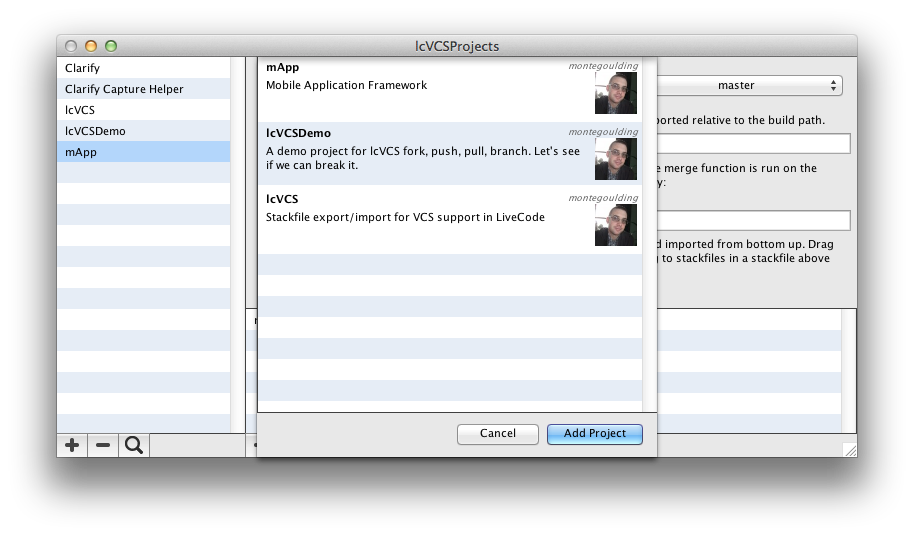
lcVCS GitHub search (click to zoom)
So now lcVCS is both a way to help you version control your app, plugin or library and a way to deliver your open source plugin or library into the hands of other LiveCoders just busting to help you out with a contribution or two.
The lcVCS project is open source and licensed under the GPL 3 and is available on GitHub. Because lcVCS imports itself you will also need to get the current versions of the stackFiles which are available from the downloads page under a free or paid account at mergExt. The simplest thing to do is get the stackFiles then add lcVCS as a project so that you can update it as new versions become available. You will also need to install mergJSON (also available under a free or paid account) which is the super fast dual-licensed JSON parser external lcVCS is built on. While you’re there why not check out what mergExt can offer for your apps?
If you’re interested to start using lcVCS I am available for hands on consulting to help you and your team get up and running. There’s also some rules your project will need to follow in order to successfully transition:
If you use IDs in scripts anywhere (such as setting the icon of a button) then replace it with a name based reference.
Implement lcVCSExport handlers to ensure everything is set back to defaults during the export.
If you have any custom objects or libraries that maintain custom property sets that store IDs then implement a plugin to support it. The plugin api is quite simple and there’s a number of examples demonstrating their use. If possible contribute the plugin back to the project so we can maintain them centrally.
Limit object references between stackFiles where possible. Where it’s not possible ensure that there are no circular references. For example, stackFile A has an object reference to an object in stackFile B while stackFile B has an object reference to an object in stackFile A.
Order your stackFiles so that the stackFiles that have object references to objects in other stackFiles are imported and exported after the stackFiles they refer to. The stackFiles list in the lcVCSProjects stack can be re-ordered by drag and drop.
If you have object references to objects that no longer exist (such as icons referencing deleted images) clear the property.
Join the conversation