
There are a lot of things to tell you about LiveCode 7.0, and of course we will be writing about many of them in upcoming blog posts. For this blog I’m going to tell you bit about some of the new chunk types that have been introduced. There are 7 new chunk types if you count the new synonym, which I do if only to allow for the chiastic blog title – byte, codeunit, codepoint, trueWord, segment, sentence and paragraph.
Arguably the most important new chunk types are the sentence and trueWord chunks. These new chunk types make analysing text much easier than it was previously. Suppose you want to know how the first sentence of Mary Shelley’s Frankenstein compares to the rest of the text, in terms of the number of words it contains (I’m sure you do). Well you can find out if it is smaller than average with ease:


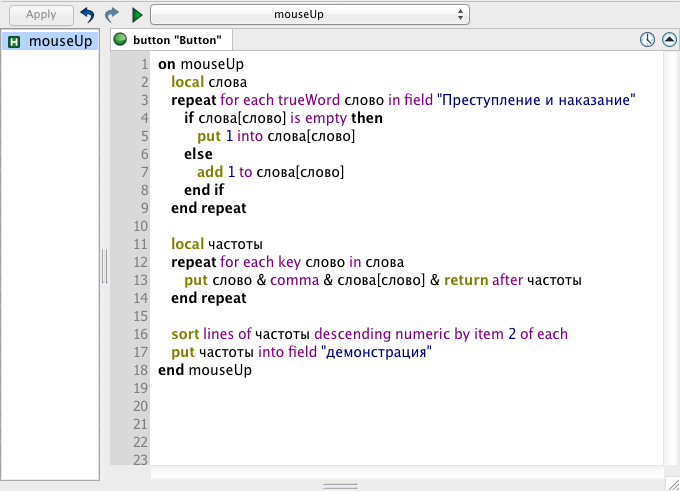
But you needn’t be restricted to English texts, control names or indeed variable names in 7.0. Perhaps you’re interested in the frequencies of different words in the original Russian of Dostoevsky’s Crime and Punishment (I’ve no doubt that you are). Simply repeat over the trueWords of your “Преступление и наказание” field, count, and process.

The most important feature of the new trueWord and sentence chunks is that they draw on a large base of rules about sentence and word boundaries provided by the ICU library. This means in particular that word breaks are identified in places that would be impossible to detect in older versions of LiveCode. Suppose you’ve got a sentence written in Chinese which you want to divide into its constituent words (I’m absolutely certain you have). In this example I’m just using “Hello World.”
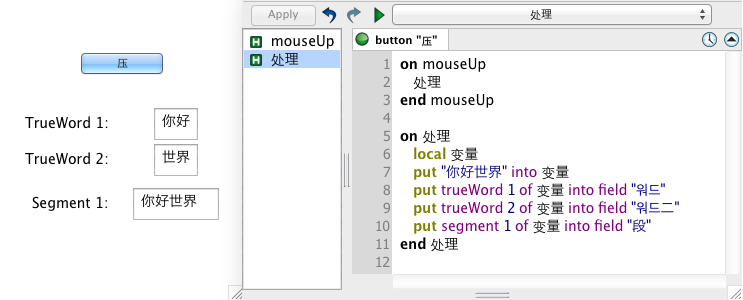
The segment chunk, a synonym of the old word chunk, looks for space characters as delimiters, whereas the trueWord chunk uses the ICU data to split the string correctly.
Note that in addition to all the variables, LiveCode 7 is perfectly happy to have a handler named 处理 (“process” – although I don’t claim it is conjugated correctly for this context)! I also exported the snapshot of that stack to a file named “快照.png” from the message box because… well, just because.
![]()
Also added is the paragraph chunk. It is very similar to the existing line chunk except it can also be delimited by the Unicode paragraph separator character. This means that it is more useful for processing text which is or will be displayed in a field – field text breaks are precisely the delimiters of the paragraph chunk.
Finally there are the codepoint and codeunit chunks. Well, there’s also the byte chunk, but that should only be used for binary data. For greater detail on these chunks, you should consult the release notes for LiveCode 7.0., but I thought I’d mention a potential application that occurred to me. Imagine, if you will, that you want to make sure Georges Perec and his translators had done a good job with their constrained writing (of course you do). Well the codepoint chunk (with a bit of help from normalizeText) can help you out!

Now here’s a challenge. What’s the longest chunk expression you can find a genuine use for? Put codeunit a of codepoint b of char c of token d of trueWord e of segment f of item g of sentence h of paragraph i of line j… (of field k of group l…)
To upgrade to this release please download the installers directly at: http://downloads.livecode.com/livecode/
To view the release notes please visit: http://downloads.livecode.com/livecode/7_0_0/LiveCodeNotes-7_0_0_dp_1.pdf
read more
Recent Comments