
As a follow-on from the LiveCode’s new newsletter and Geoff Canyon’s blog post on using ChatGPT to write LiveCode (which you can read here if you missed it!) I thought I’d write a little bit about how language models like ChatGPT are made.
You’ve probably seen a lot about the what, where, who, and why of ChatGPT, but maybe a bit less about the how. I spent some time studying language model neural networks as part of my Master’s project at university, so hopefully I can shed a bit of light on how chatbot AIs are made.
What is a language model?
Let’s start with the question, what actually is a language model?
A language model is a probability distribution over words or series of words. As humans, we intrinsically know a huge amount about language and all its rules. If I show you some incomplete sentences you’ll be able to assess the likelihoods of different missing words without ever really needing to think about it.
`I brush __ teeth`It seems pretty obvious to us that the missing word is probably “my” or maybe something like “the”. We know that the probability of the missing word being “Edinburgh” or “field” is pretty unlikely.
`LiveCode is a programming ___`Similarly, some of the words that might spring to mind are “language” or “tool”. We know, without too much thought, that it’s unlikely to be “jumping” or “the”.
We gain this huge amount of knowledge from years of being exposed to language constantly, which is why it can be difficult to try to replicate natural sounding writing with machine learning. As you can imagine, language models need very large datasets to learn all the implicit rules of a language that we know. OpenAI’s GPT-3 model used around 570 GB of text for its training. Given that a letter is a byte (for ASCII characters) and that English words have an average of 5 letters, then a 100,000 word book would take up about 0.5 MB (assuming that it’s in plaintext and we can ignore any fancy formatting). To create a 570 GB dataset of text, we’d need over a million books – which isn’t a small amount!

So how do we turn all that training data into something that can create sentences? Instead of jumping straight into the much more complex world of neural networks, we’ll have a look at the simplest type of language model first – the unigram model.
Unigram Language Models
A unigram language model assigns a probability to a word occurring based on how often it appeared in a training dataset. Let’s get the maths bit out the way first:
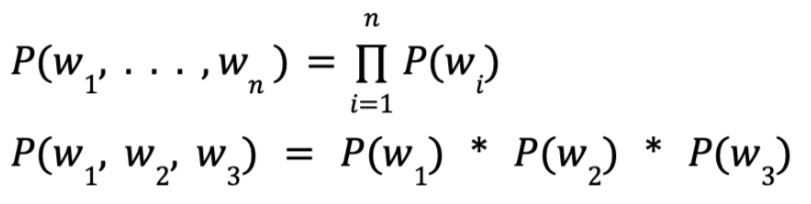
What this says is that for a unigram model the probability of our phrase w1 w2 w3 (let’s say “the dog runs”) is the same as the sum of the probabilities of each individual word appearing.
The probabilities of each word are calculated from how many times they appear in the training data divided by the total number of words.
As you might guess, there are some problems with this model. The probability given by the unigram model for our phrase “the dog runs” is the exact same as it would give “dog the runs”. As humans we know that one of those phrases is more valid than the other, but to a unigram language model they’re equally likely.
Our unigram model also never considers the probability of a word based on the other words that have come before it. Words like “a” and “the” are used very frequently in English, so they’ll have much higher probability scores than other words in the dataset. This means that a nonsense sentence like “the and the the a is the” would be given a much higher probability than a valid sentence using words that appeared less often in the training data.
This is where other n-gram models come in.
N-gram language models
The term n-gram refers to a sequence of n words – a 2-gram (known as a bigram) is a 2 word sequence like “the dog” or “dog runs”, a 3-gram (also known as a trigram) is a three word phrase like “the dog runs”, and so on. Our unigram model is actually an n-gram model, for the case where n = 1.
The maths for our bigram (n=2) model looks like this:
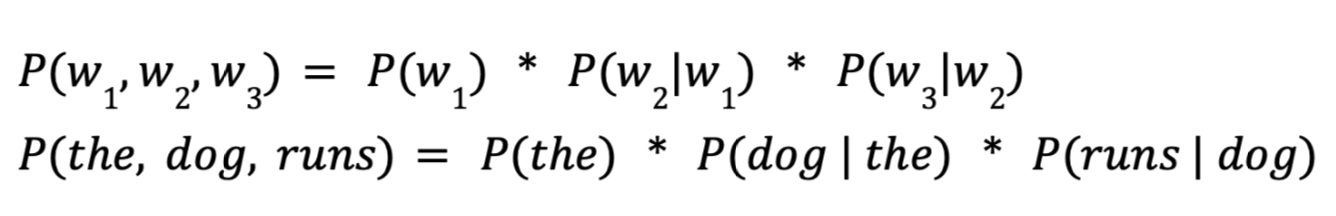
To put that in words, the probability of our phrase “the dog runs” is equal to the product of the probability of “the”, the probability of the word “dog” appearing directly after “the”, and the probability of “runs” coming after “dog”. The probability of each word is only considered relative to the word directly before it.
The trigram (n=3) follows the same pattern:
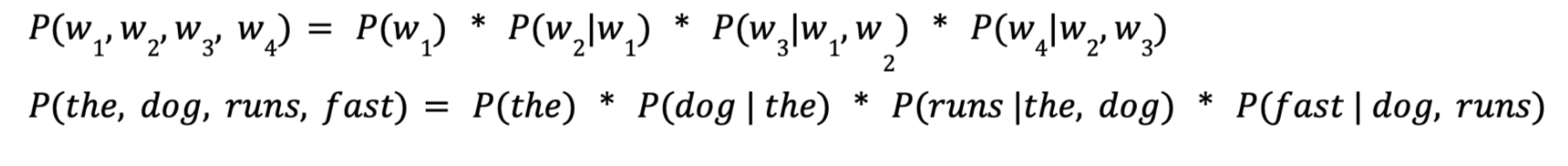
If you’ve ever tried repeatedly choosing the suggested next word that pops up on your phone’s keyboard, then you’ll probably be aware of a problem that n-gram models with low values of n can run into. Here’s one I created using the suggested words on my phone:
“This is because the name of the place is a good thing to be able to get the key to the key”
There are sequences within the sentence that make sense like “this is because”, “the name of the place”, and “to get the key”, but overall we get a meaningless nonsense sentence.
There are some shortcomings with something as simple as an n-gram language model, which is where we consider alternative options – like neural networks. I’m not going to go too in-depth on the background of neural networks here or we’d be here all day, but there are lots of great explainers all over the internet if you’re interested in finding out more.
If you ask ChatGPT how it works, it will tell you something along the lines of this:
“ChatGPT is a large language model that uses deep learning techniques to generate human-like text. It is based on the GPT (Generative Pre-trained Transformer) architecture which uses a transformer neural network to process and generate text. The model is pre-trained on a massive dataset of text, such as books, articles, and websites, so it can understand the patterns and structure of natural language. When given a prompt or a starting point, the model uses this pre-trained knowledge to generate text that continues the given input in a coherent and natural way.”
Let’s unpack that a bit.
What is the Generative Pre-trained Transformer architecture?
The Generative Pre-trained Transformers (which we’ll refer to as GPT from here) are a series of language models from OpenAI. In particular, we’re interested in GPT-3.5 which ChatGPT was created with. GPT-3.5’s architecture uses a type of deep learning model called transformers, which were first proposed by a team at Google Brain in 2017.
There’s a few key differences that make transformers stand out from some of the other types of neural networks used for natural language processing. Unlike some other neural network models, transformers can process an entire input at once – rather than processing a sentence word by word, they can digest the whole thing at once. The big benefit of this is that you can train much faster, and therefore use even bigger datasets.
Transformers also use a technique called attention, which allows them to pay greater focus to some parts of the data, and less to others. Often books might have long and descriptive sentences, where there’s a lot of words, but the core meaning is just in a few. Depending on what information we’re trying to extract, some of the words will be more or less important.
Finally, how do we get to ChatGPT from our GPT-3.5 model? The answer is a process called fine-tuning.
Fine-tuning ChatGPT
Fine-tuning is a process where the existing model GPT-3.5 is used as a basis to create a new model, which is being optimised to best perform its given task. ChatGPT was fine-tuned using two types of learning – reinforcement learning and supervised learning.
Supervised learning
Supervised learning involves training a machine learning model using labelled training data. If you want your model to predict y, given an input of x, then your supervised learning training dataset would include a series of inputs (x1, x2, …, xn) and a series of corresponding labels (y1, y2, …, yn).
For the first step of ChatGPT’s fine-tuning, a labelled dataset was created with prompts from a prompt dataset, and corresponding outputs written by humans. This fine-tuning helps to update our machine learning model to create what we’ll call the Supervised Fine Tuning Model (SFT model).
Reinforcement learning
The next step in the fine-tuning was reinforcement learning. In reinforcement learning a reward model is created, which ‘rewards’ good answers and ‘punishes’ worse answers. To create this reward model, human labellers ranked a number of different outputs to the same prompts.
In the (completely made-up) example below, all three responses are technically correct, but C is a better answer than A and B.

The reward model, created with this ranked data, is used to score new outputs from the SFT model. The scores from the reward model are used to optimise responses from the SFT, through an iterative process of creating an output, receiving a score for that output from the reward model, and updating the SFT model’s strategy for creating outputs.
Finally, this optimised model is what you interact with. Currently ChatGPT is in a research phase, so it’s likely that the fine-tuning steps we discussed here will be repeated using the feedback to prompts from everyone using it now.
I hope that this discussion of the basics of language models was informative (and maybe even interesting!). If you want a more in-depth and technical discussion of this then you can read OpenAI’s paper on InstructGPT (ChatGPT’s sibling) here.
3 comments
Join the conversationJim Lambert - March 29, 2023
jiml@netrin.com Holly, thank you for this interesting and informative primer!
Andreas - March 29, 2023
Thanks for this very well written and informative article!
Using LiveCode with AI/ML APIs has great potential, both in the development/coding process itself and in end-user applications. Exciting times!
Andy - March 30, 2023
Thanks for an excellent explanation of how the learning models work. I been playing with GPT-3 and Livecode for a while which although can generate Livecode script still has a long way to go before we get replaced by AI. Now GPT-4 is truly amazing in the way it spits out valid code. It understands Livecode much better than it’s predecessor, gives very good concise code and explanations of how the code functions. One still has to massage the code but, it’s in my estimation about 90% accurate. GPT-5 will I think give us coders pause for thought.